8 System Response Functions
System response functions specify how a system responds to a given hazard. In RMC-TotalRisk, a system response function defines the conditional probability of failure for various hazard levels, such as WSEs.
In dam and levee safety risk analyses, analysts develop system response functions for multiple potential failure modes (PFMs). Common PFMs include seepage and piping, erosion and bank caving, and overtopping. Each PFM may result in different consequence outcomes, so analysts should keep PFMs distinct in a risk analysis.
RMC-TotalRisk allows users to define system response functions using an event tree, parametric function, tabular function, bivariate tabular function, or a composite of multiple functions. The following subsections describe each input option in detail.
8.1 Event Tree Response Function
Event tree analyses (ETAs) represent the logic of how an initiating event, like a flood or earthquake, can lead to various types of damage and failure [3]. An event tree consists of a sequence of interconnected nodes and branches [6]. Each node corresponds to an uncertain event (e.g., a crack forming in an embankment) or an uncertain state of nature (e.g., the existence of adversely oriented joint planes). Branches originating from a node represent the possible events or states of nature that could occur. Probabilities are assigned to each node to quantify the likelihood of each event or condition, conditional on the occurrence of all preceding events in the tree. For more details on event tree calculations in RMC-TotalRisk, refer to [1].
To create an event tree response function, right-click on the System Responses folder in the Project Explorer (Figure 8.1) or navigate to Project Menu > System Responses and select Add Event Tree Response…. A dialog will appear, prompting you to enter the dataset name and select an event tree template to import. This example uses the Basic template to demonstrate how to build an event tree from scratch, but you can also choose from a variety of default or user-defined templates.
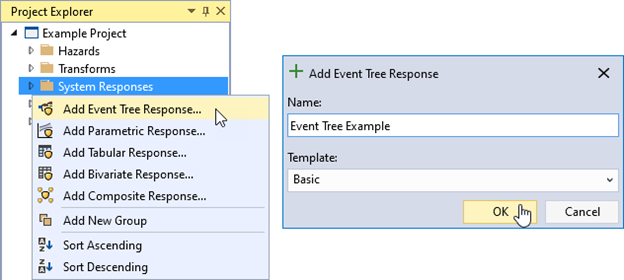
Figure 8.1: Create new event tree response function.
After creating the new event tree response function, the Tabbed Documents area automatically opens, and the Properties window displays the event tree properties (Figure 8.2). In the Properties window, you can configure the name, description, hazard type, hazard units, hazard interpolation, probability interpolation, and selected event tree node properties. The interpolation transforms define how the data is interpolated when sampling values between hazard levels.
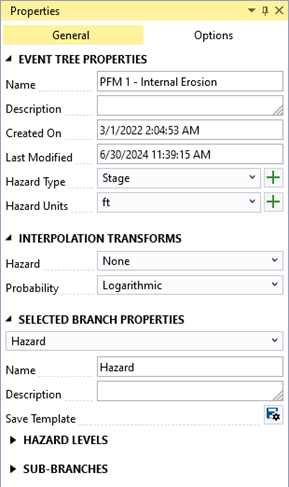
Figure 8.2: Event tree response function properties.
8.1.1 Terminology
This section defines RMC-TotalRisk’s event tree terminology [1].
-
Node: Represents a branching point in the event tree, signifying a random event or state. Event trees include four types of nodes:
 Initiating Hazard Node: Always the first node in the event tree. This node defines the hazard levels and links system response probabilities to the hazard function. Enter only hazard levels for this node, not hazard exceedance probabilities. To improve the accuracy of dam and levee risk assessments, define at least five hazard levels. Start with a hazard level with a near-zero probability of failure and progress to a level exceeding the crest height. Include intermediate levels with critical features or inflection points, such as the normal pool or the spillway invert for dams.
Initiating Hazard Node: Always the first node in the event tree. This node defines the hazard levels and links system response probabilities to the hazard function. Enter only hazard levels for this node, not hazard exceedance probabilities. To improve the accuracy of dam and levee risk assessments, define at least five hazard levels. Start with a hazard level with a near-zero probability of failure and progress to a level exceeding the crest height. Include intermediate levels with critical features or inflection points, such as the normal pool or the spillway invert for dams. Chance Node: Represents the probability of an event occurring at each hazard level defined in the initiating hazard node. You can define probabilities as a single value for all hazard levels (single value), as unique values for each hazard level (multi-value), or by referencing another source (see “reference node”).
Chance Node: Represents the probability of an event occurring at each hazard level defined in the initiating hazard node. You can define probabilities as a single value for all hazard levels (single value), as unique values for each hazard level (multi-value), or by referencing another source (see “reference node”). Reference Node: Functions like a chance node but pulls probabilities from a previously defined response function or node in the event tree instead of defining them directly at the node.
Reference Node: Functions like a chance node but pulls probabilities from a previously defined response function or node in the event tree instead of defining them directly at the node. Remainder Node: Represents the probability remaining after accounting for all other chance and reference node probabilities at the current branching point. For example, if an event has two potential outcomes, the remainder node accounts for the probability that neither outcome occurs. The software computes the remainder probability automatically; users cannot modify it.
Remainder Node: Represents the probability remaining after accounting for all other chance and reference node probabilities at the current branching point. For example, if an event has two potential outcomes, the remainder node accounts for the probability that neither outcome occurs. The software computes the remainder probability automatically; users cannot modify it.
Branch: The line connecting two nodes in the event tree.
End Node: A node with no downstream branches, representing the final state in a sequence of events. This is also called a leaf node or terminal node..
Pathway: A unique sequence of events representing a potential failure progression. The probability of a pathway equals the joint probability of all nodes in the series from the initiating hazard node to the end node. This is also referred to as a path, sequence, connection, or root-to-node.
Upstream Nodes: Nodes located to the left of a selected node in the tree. These nodes must occur before the selected node’s event. Upstream nodes are also called parent nodes, conditional events, or preceding nodes.
Downstream Nodes: Nodes located to the right of a selected node in the tree. These nodes occur after the selected node’s event. Downstream nodes are also called child nodes, conditional events, proceeding nodes, or subsequent nodes.
Node Probability: Represents the probability of the selected node event occurring, conditioned on the occurrence of all upstream nodes.
Event Likelihood: Represents the probability of a node event occurring at a given hazard level. This is the joint probability of the selected node event and all its upstream nodes.
8.1.2 Navigating an Event Tree
You can move the event tree around the workspace by clicking and dragging the background canvas with any mouse button. Use the mouse wheel to zoom in and out. When you hover over a node or branch, it highlights. Left-click to select nodes or branches, and right-click to display context menu options.
When you hover over a node, a toolbar appears above it, as shown in Figure 8.3. You can also access these toolbar options by right-clicking on a node.
Figure 8.3: Event tree node toolbar icons.
 Delete Branches: Click this icon to remove all child branches from the selected node.
Delete Branches: Click this icon to remove all child branches from the selected node. Copy Branches: Click to copy the child branches into memory for pasting elsewhere.
Copy Branches: Click to copy the child branches into memory for pasting elsewhere. Paste Branches: Click to paste previously copied branches onto the current node.
Paste Branches: Click to paste previously copied branches onto the current node. Add New Branch: Click to create a new branch from the selected node.
Add New Branch: Click to create a new branch from the selected node.
When you hover over a branch, a toolbar appears above its name, as shown in Figure 8.4. These options are also available by right-clicking on the branch. To rename a branch, double-click on it or use the branch properties.
Figure 8.4: Event tree branch toolbar icons.
 Delete Branch: Click to remove the selected branch and all its child branches from the event tree.
Delete Branch: Click to remove the selected branch and all its child branches from the event tree. Branch Properties: Click to edit branch properties such as name, description, and probabilities directly in the workspace.
Branch Properties: Click to edit branch properties such as name, description, and probabilities directly in the workspace. Save Template: Save the event tree as a template for future use. This option is only available on the initiating hazard branch.
Save Template: Save the event tree as a template for future use. This option is only available on the initiating hazard branch.
8.1.3 Customizing an Event Tree
The Options tab in the event tree Properties window provides tools to customize your event tree’s appearance and layout (Figure 8.5).
Height: Adjusts the height of each node in pixels. Increasing the height beyond 70 pixels allows node names to span multiple lines.
Width: Sets the horizontal spacing, in pixels, between nodes.
Smooth: Controls the smoothness of the connector lines between nodes.
Extend: If selected, extends the terminal (leaf) nodes to align with the right-most column in the event tree.
Background Color: Changes the background color of the event tree workspace.
Gridline Color: Sets the color of the background gridlines in the workspace.
Node Fill: Specifies the fill color for the selected node.
Node Stroke: Defines the outline color for the selected node.
Reset: Restores all options to their default settings when clicked.
Zoom Scale: Adjusts the zoom scale factor for the event tree workspace. A value of 1 represents the base zoom level.
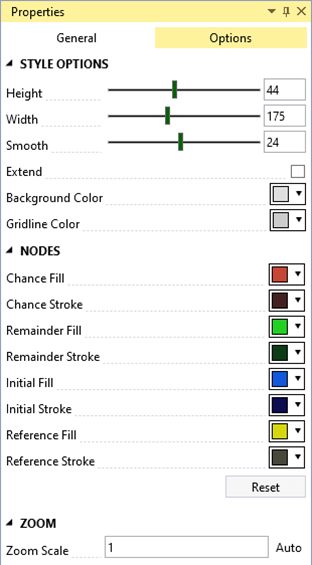
Figure 8.5: Event tree style options.
8.1.4 Building an Event Tree
This example demonstrates how to build an event tree for spillway erosion. The sequence of events includes: pool elevation results in spillway flow, grass erodes from the spillway, headcut initiates, headcut advances to the control section, control structure fails, unsuccessful intervention, and breach.
-
Define the hazard. Select the initiating hazard node branch, Hazard, by clicking on it. Once selected, edit its properties in the Properties window under the Selected Branch Properties subsection (Figure 8.6). Alternatively, click the Branch Properties button in the event tree node toolbar to edit the branch. Rename the branch to “Pool Elevation.”
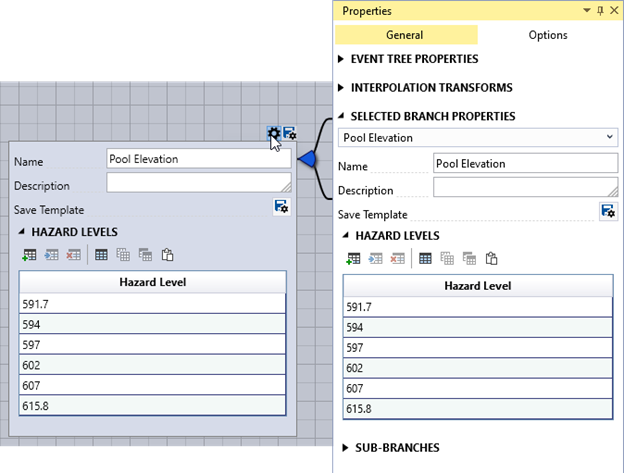
Figure 8.6: Edit the node properties from either the node toolbar or Properties window.
Enter hazard levels. Use the table editing tools to input the desired hazard levels.
Delete the default chance node. Remove the chance node added by default by clicking the delete button
in the toolbar, or by using the Sub-Branches Properties section of the initiating hazard node. Confirm the deletion when prompted by clicking Yes.Add a new node. Add the next node in the event tree using one of the following methods: Click the Add New Branch button
in the node toolbar, use the right-click node context menu on the node, or navigate to the Sub-Branches Properties section in the Properties window. After adding the node, use the Node Properties Editor to rename it, add a description, and define the event’s probability for each hazard level specified in step 1 (Figure 8.7).
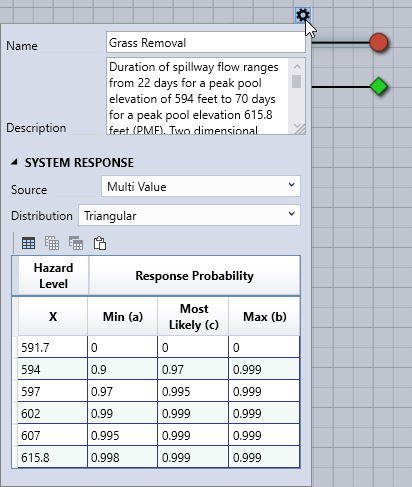
Figure 8.7: Properties for the Grass Removal probability event tree node.
- Complete the event tree. Continue adding nodes and defining their properties until the event tree is fully developed (Figure 8.8).
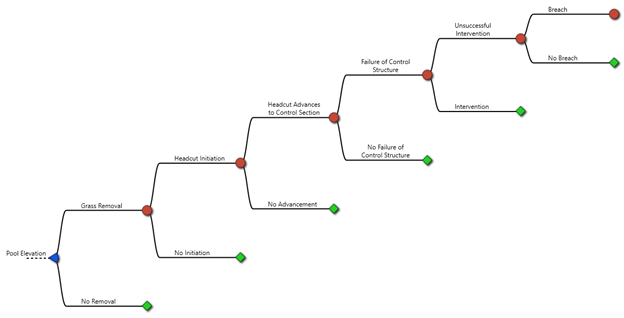
Figure 8.8: Completed spillway erosion event tree.
8.1.5 Exploring Event Tree Results
The Tabbed Document contains three tabs: Event Tree, Response, and Diagnostics, each offering tools to explore the event tree analysis results.
The Event Tree is used to build and edit the event tree, as described in earlier sections.
The Response tab displays a graphical representation of the system response function for each hazard level (Figure 8.9). This function, commonly referred to as a fragility curve, represents the probability of failure for each defined hazard level. You can export the function data as tabular data using the Export Plot Data button.
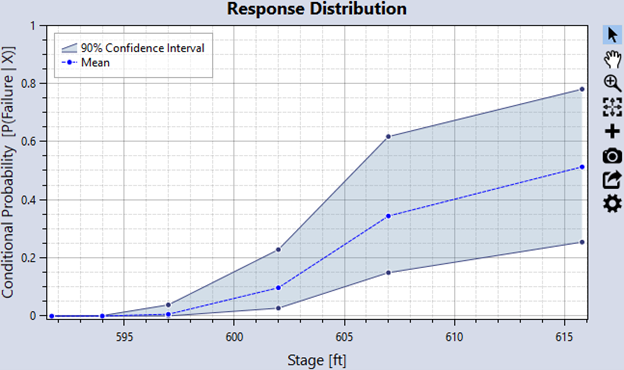
Figure 8.9: System response probability function result from event tree.
- The Diagnostics tab provides tools for reviewing and validating the event tree calculations. The left side of the Diagnostics tab offers options for Node Filters, Model Parameters, and Plot Options (Figure 8.10). Details for each option are provided below.
Figure 8.10: Event tree diagnostic viewing options.
Node Filters
Show Remainder Nodes: Toggles the display of remainder nodes in the results.
Combine Remainder Leaves: Combines terminal remainder nodes, which often represent non-failure conditions, into a single result.
Leaf Nodes Only: Displays only terminal leaf nodes (nodes without child branches).
Model Parameters
Monte Carlo Iterations: Specifies the number of Monte Carlo iterations used to sample the event tree for diagnostic analysis. This option is disabled if no uncertainty is present.
Hazard Level: Defines the hazard level used to calculate diagnostic results.
Plot Options
- Event Likelihood: Displays a box-and-whisker plot of the likelihood for each node occurring at the selected hazard level (Figure 8.11).
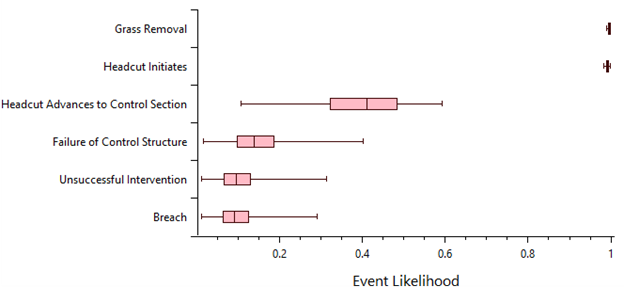
Figure 8.11: Event tree diagnostics event likelihood plot option.
- Correlation to SRP: Shows the Pearson correlation coefficients for how node probabilities correlate with the overall SRP. Chance nodes have a positive correlation with the SRP, whereas remainder nodes have a negative correlation. The absolute size of the correlation coefficient indicates the strength of the association with SRP. The nodal correlations to SRP display as a ranked tornado plot (Figure 8.12).
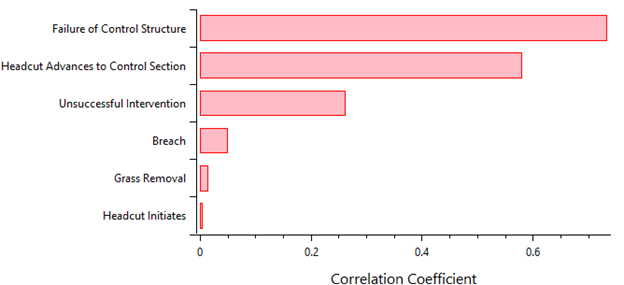
Figure 8.12: Event tree diagnostics tree node correlation to SRP plot.
- Sensitivity Index: Displays each node’s first-order sensitivity index, indicating its contribution to the variance in the SRP (Figure 8.13). A high sensitivity index suggests that reducing uncertainty for that node could significantly affect the overall SRP.
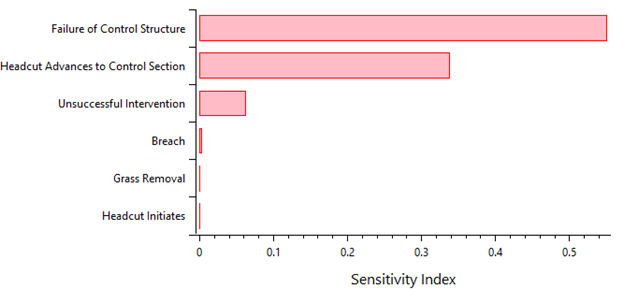
Figure 8.13: Event tree diagnostics tree node sensitivity indices.
- Node SRP Scatter: Plots the sampled probabilities of a node against the overall SRP for each Monte Carlo iteration. Nodes with strong correlations to the SRP show clear trends in this scatter plot (Figure 8.14).
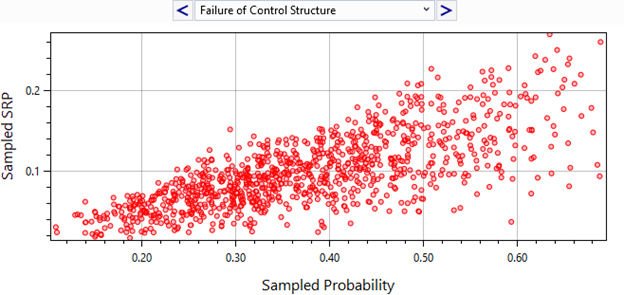
Figure 8.14: Event tree diagnostics tree node probability to SRP scatter plot.
- Tabular: Displays a table of node probabilities and the overall SRP for each Monte Carlo iteration (Figure 8.15). Use the table’s column statistics feature to verify sampling distributions (Figure 8.16).
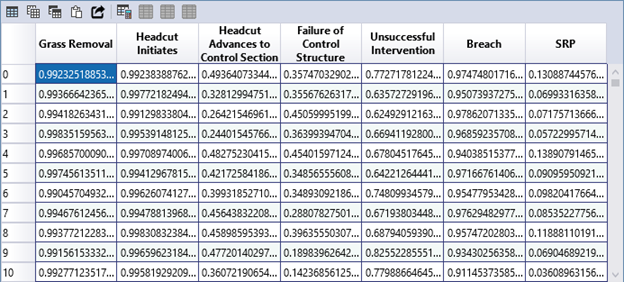
Figure 8.15: Event tree diagnostics tabular output.
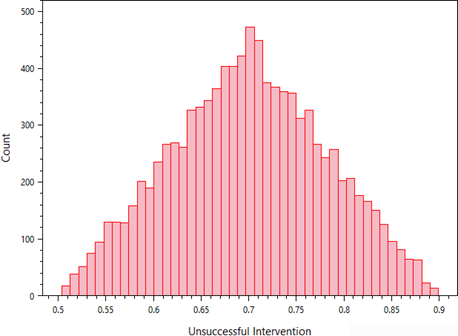
Figure 8.16: Column statistics for the Unsuccessful Interventions node’s sampled probabilities, confirming that the node distribution (triangular) is being sampled correctly.
8.2 Parametric Response Function
This option enables you to define a system response function using a parametric distribution.
To create a parametric response function, right-click on the System Responses folder in the Project Explorer (Figure 8.17) or go to Project Menu > System Responses and select Add Parametric Response…. Enter a name for the parametric response function and click OK.
Figure 8.17: Create new parametric response function.
After creating the parametric response function, the system automatically opens it in the Tabbed Documents area, and the Properties window displays its properties (Figure 8.18). In the Properties window, you can set the name, description, hazard type, and hazard units. Define the parametric distribution by setting the ERL, type of distribution, and parameters for the distribution. Once the parameters have been set, click the Compute button to generate and view the parametric response function.
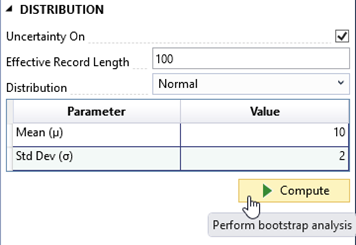
Figure 8.18: Parametric response function properties.
Additional options for computing the parametric function are available in the Options tab on the Properties window. These include bootstrap sampling, confidence intervals, the number of realizations, a pseudo random number generator (PRNG) seed for random number generation, and output probability ordinates.
Similar to RMC-BestFit, RMC-RFA, and parametric hazard functions, you can view frequency results in graphical or tabular form. For more information on these viewing options, refer to section 6.1.
8.3 Tabular Response Function
This option allows you to define a system response function using tabular data. The most common use case involves copying and pasting data from another application, such as Microsoft Excel.
To create a tabular response function, right-click on the System Responses folder in the Project Explorer (Figure 8.19) or go to Project Menu > System Responses and select Add Tabular Response…. Enter a name for the tabular response function and click OK.
Figure 8.19: Create new tabular response function.
Once you create the tabular response function, the system automatically opens it in the Tabbed Documents area, and the Properties window displays the tabular function’s properties (Figure 8.20). In the Properties window, you can configure the name, description, hazard type, hazard units, and hazard and probability interpolation transforms. The interpolation transforms define how the data is interpolated when sampling values between the specified tabular ordinates.
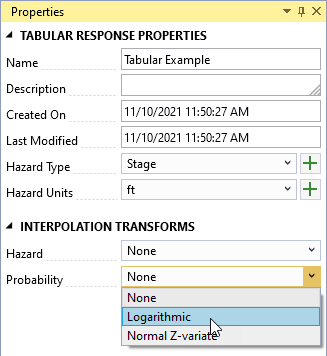
Figure 8.20: Tabular response function properties.
The Tabbed Document for a tabular response function includes a table for data entry and a graphical representation of the data (Figure 8.21). Select a distribution to define uncertainty and enter the parameters for the selected distribution at each ordinate in the tabular data. You can input data manually into the table or paste it from an external source, such as Microsoft Excel.
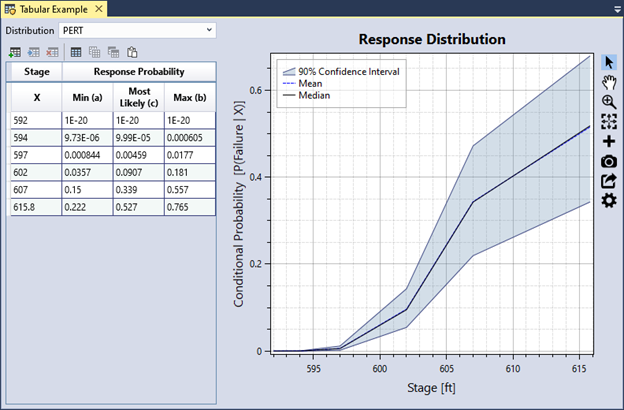
Figure 8.21: Tabular response function example.
8.3.1 Data Validation
The input data table has built-in validation. Tabular data must meet the following requirements:
The hazard values must be in ascending order.
The probability values must be between 0 and 1.
If uncertainty is defined, the uncertain ordinates must contain valid distribution parameters.
If you enter invalid data, the corresponding table cell turns red, and a tooltip explains the error, as shown in Figure 8.22. In addition, an error message appears in the Message window prompting you to resolve all errors in the data table.
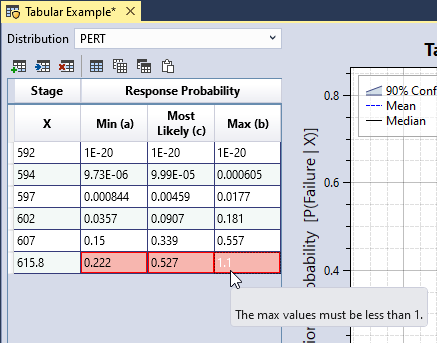
Figure 8.22: Tabular response function input data validation.
8.4 Bivariate Response Function
This option enables you to define a system response function that depends on two hazards using tabular data.
To create a bivariate response function, right-click on the System Responses folder in the Project Explorer (Figure 8.23) or go to Project Menu > System Responses and select Add Bivariate Response…. Enter a name for the bivariate response function and click OK.
Figure 8.23: Create new bivariate response function.
When you create the bivariate response function, it automatically opens in the Tabbed Documents area, and the Properties window displays its properties (Figure 8.24). From the Properties window, you can configure the name, description, primary hazard, primary hazard units, and the interpolation transforms for the primary hazard and probabilities.
Use the table tools to add the desired hazard levels for both the primary and secondary hazards, ensuring that all hazard levels are in ascending order. Assign a weight to each secondary hazard level. These weights are used during the risk computation to estimate the total system response probability for each primary hazard level. The weights must sum to 1. You can enter the weights manually or calculate them using a specified hazard function. For more details on bivariate hazard properties, refer to [1].
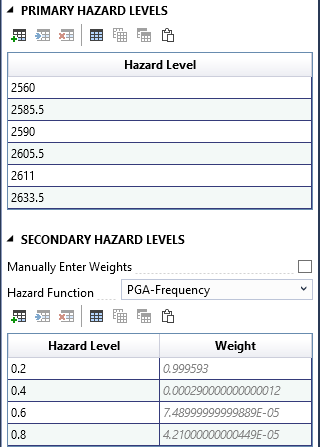
Figure 8.24: Bivariate response function properties.
As you input primary and secondary hazard levels in the Properties window, the table at the top of the Tabbed Document automatically updates, with each row representing a primary hazard level and each column representing a secondary hazard level (Figure 8.25). To complete the bivariate response function, enter the probability of failure in each cell based on the combination of the primary hazard (row) and secondary hazard (column). A graphical representation of the system response functions for each secondary hazard level appears below the table.
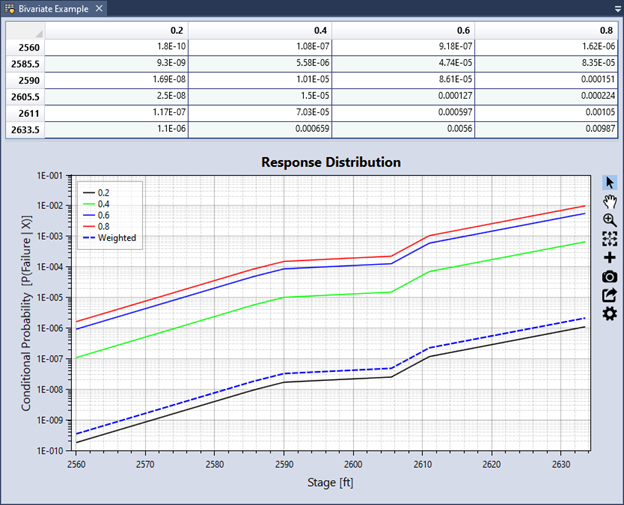
Figure 8.25: Bivariate response function graphical display.
8.5 Composite Response Function
This option allows you to combine multiple response functions into a single function by assigning weights to the individual input functions.
To create a composite response function, right-click on the System Responses folder in the Project Explorer (Figure 8.26) or navigate to Project Menu > Hazards and select Add Composite Response…. Enter a name for the composite response function and click OK.
Figure 8.26: Create new composite response function.
After creating the composite response function, it automatically opens in the Tabbed Documents area, and the Properties window displays its properties (Figure 8.27). In the Properties window, you can configure the name, description, hazard type, hazard units, and input response functions. Use the Response Functions table to define the input functions. Click the Add Row(s) button in the table toolbar to add rows for the input functions. Ensure that the response function weights sum to 1. If the system response functions are competing, uncheck the Is Mixture checkbox and select a Dependency type: Independent, Perfectly Positive, or Perfectly Negative.
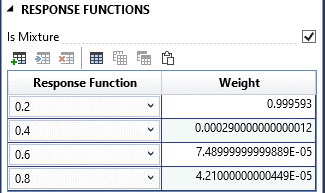
Figure 8.27: Composite response function properties.
The Tabbed Document for a composite function includes a graphical representation of the composite function (Figure 8.28).
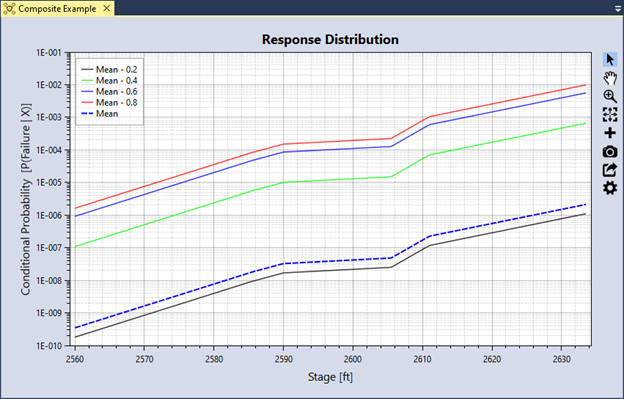
Figure 8.28: Composite response function graphical display.